
If you’ve worked with microservices, you know how hard it is to solve for shared capabilities. Authorization is one such capability. Most services will need some kind of authorization, and so you want a clean authorization implementation that every service can reuse. But authorization as a domain is messy. Authorization logic blurs with domain-specific information, and data needed to evaluate authorization decisions heavily overlaps with application data.
This means that when trying to extract authorization out into its own service, it ends up being challenging to draw a clean separation.
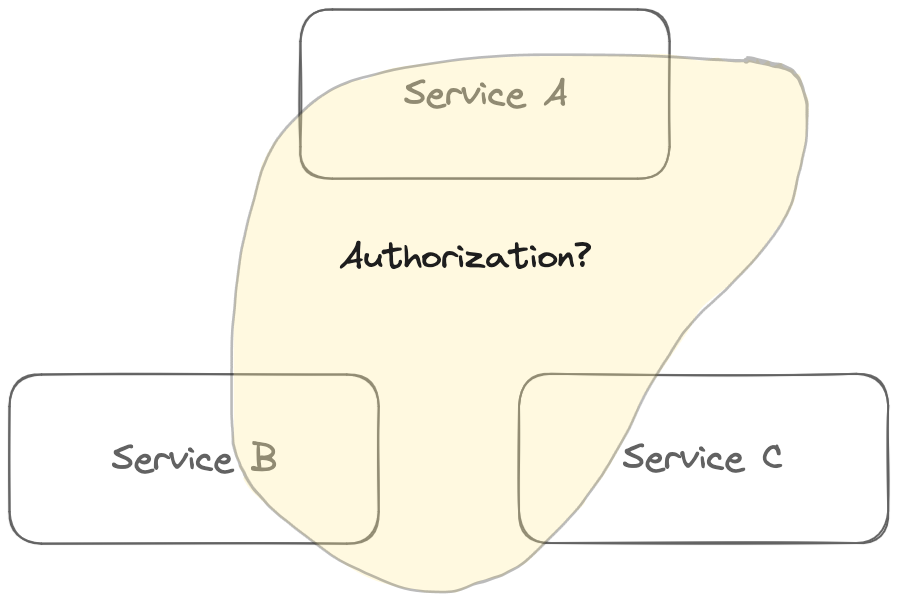
Our ideal version of authorization as a shared capability sharpens these lines, so you can integrate it with minimal overhead to any given application. A key consideration is that you shouldn’t need to synchronize data to a different service, just to evaluate authorization logic that could have all been handled locally.
To this end, we built a logic language for expressing authorization called Polar. It’s built to allow multiple teams to build an authorization model expressing both shared and domain-specific logic.
And then we made it possible to run Polar over multiple data stores, so that it can do authorization using shared data stored centrally, and application data stored alongside the application.
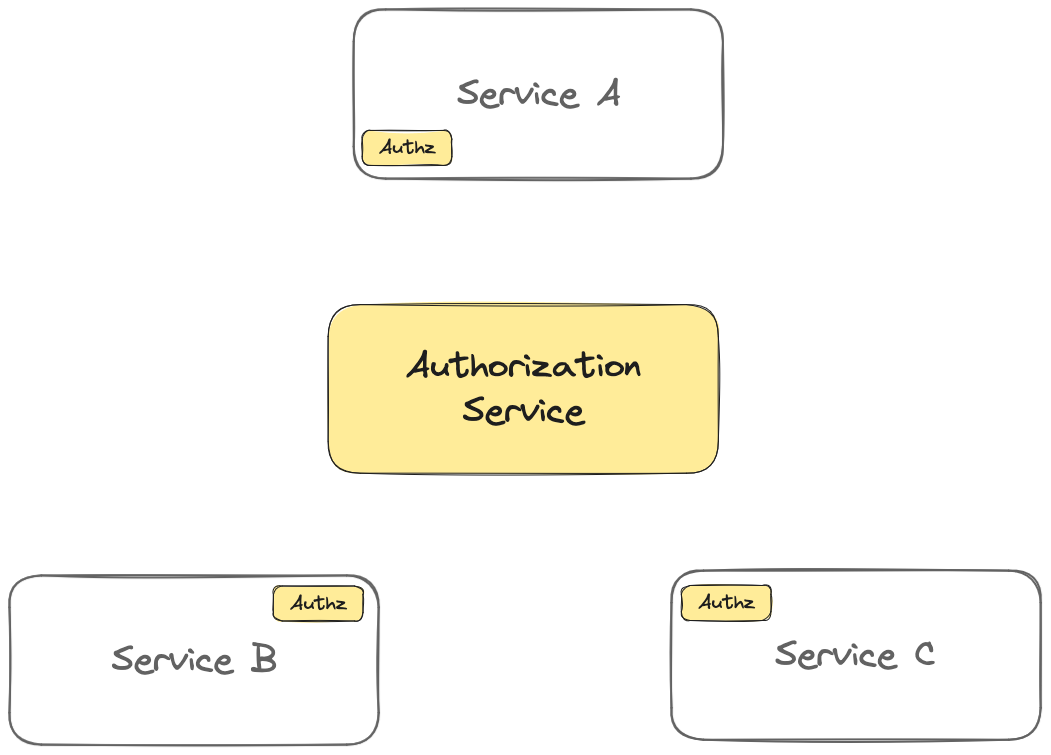
We call the resulting architecture Distributed Authorization. Here’s how we built it.
Scenario: Service-Oriented GitHub
Imagine you’re building an application like GitHub, but with a service-oriented architecture. It’s common that application-specific functionality like “repository issues” would be decoupled from authorization and permission controls like “managing organizations and user roles”.
So let’s say you have two services: AuthzService and IssuesService
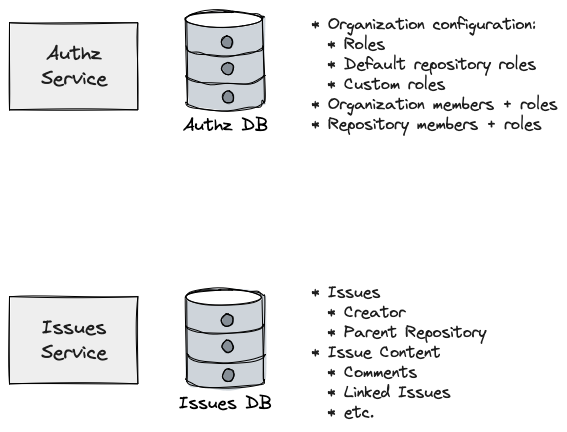
The AuthzService knows everything authorization-related about Organizations: who belongs to those organizations, what roles they have, what custom roles they’ve created. It also manages authorization data on Repositories, like which organization owns the Repository, who the members are, and what roles they have.
Meanwhile, the IssuesService deals with everything issue-related: who created the issue, what repository it belongs to, and so on.
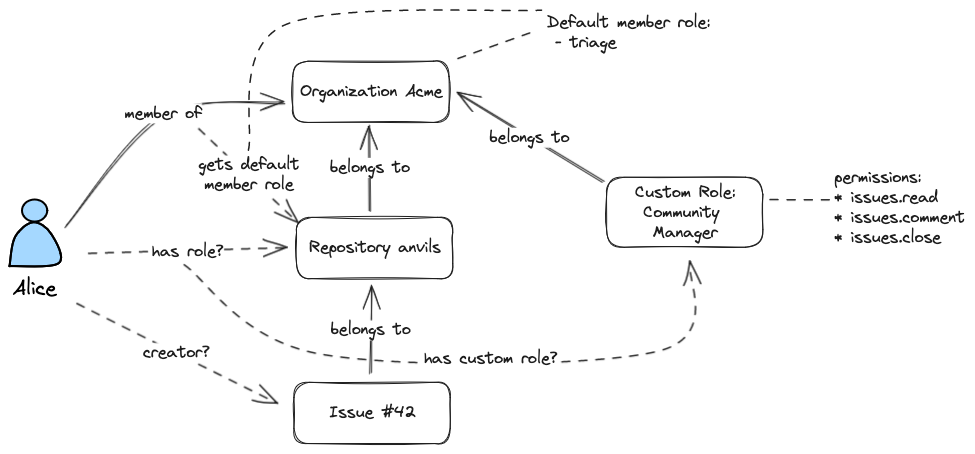
Let’s take as an example: the user Alice wants to close issue #42 on repository acme/anvil. The IssuesService wants to know if Alice is allowed to do this, and will make an API request to the AuthzService to find out.
This is a simple question, but in a mature application like GitHub, the logic gets complex. For example, GitHub has organization roles, customizable default repository roles, custom roles, issue creators, and public/private repositories. All of these impact the authorization logic:
And authorization goes beyond simple yes/no questions like this. As put really nicely by wkirby on Hacker News:
Permissions have three moving parts, who wants to do it, what do they want to do, and on what object. Any good permission system has to be able to efficiently answer any permutation of those variables. Given this person and this object, what can they do? Given this object and this action, who can do it? Given this person and this action, which objects can they act upon?
which acts a force multiplier on all of the above complexity.
Given all this, a shared authorization capability for this application has to be able to:
- express the above logic, which spans the Authz and Issues domains
- use data stored in both the AuthzService and IssuesService
- support yes/no questions as well as more flexible “list” questions
Let's start with the logic. From there, we'll explain how our approach to logic let us solve some tricky data problems. We’ll demonstrate the concepts with examples that apply them to both yes/no and list questions.
Polar: A prolog-inspired language that transpiles to SQL
Polar is our declarative approach to authorization logic that spans multiple services. Polar is inspired by logic programming languages like Prolog, Datalog, and miniKanren. Under the hood, Polar transpiles to SQL over a custom data model, which does the heavy lifting of query planning and fast data access.
Here’s a fairly minimal example of a Polar policy:
allow(user: User, "read", org: Organization) if
has_role(user, "member", org);
has_role(User{"alice"}, "member", Organization{"acme"});There’s an allow ”rule” that says:
- a
user(of typeUser) is allowed toreadanorg(of typeOrganization) - if the
userhas the rolememberon thatorg
There’s also a solitary has_role rule with no if and no conditions. These are called facts — unconditionally true information. In this case, the fact is asserting that the user with id: alice is a member of the organization with id: acme.
This Polar policy expresses:
- a simple piece of role-based access control logic: org members can read that organization
- a small piece of factual data assigning the member role to alice.
To use this policy, you can query it. The theoretical foundations of this come from logic programming and first order logic. For a deeper dive, I’d recommend checking out The Power of Prolog.
For today, there are two main facets of logic programming that you’ll want to wrap your head around:
- Inference logic (how Polar evaluate rules)
- Unification (the core “pattern-matching algorithm” of Polar)
Interlude: Logic Programming
Rules express logical properties about the world: “this statement is true if these other things are also true”. The syntax of rules makes them look a little like functions, but they resolve logically/declaratively rather than imperatively. It can still be helpful though to think in terms of “calling” rules.

Inference says that “Given a user alice who has the member role on the acme organization, it follows that allow(alice, "read", acme) is true. That is, we infer that the allow rule is true based on the fact that the has_role condition is satisfied.
Unification is effectively a fancy pattern matching algorithm that combines variable assignment + comparisons into one operator.
For example, the following are all examples of simple unification:
1 = 1 # two concrete values, behaves like comparison true
1 = 2 # false
x = 1 # behaves like assignment, the variable `x` now has value 1
x = 1 # `x` is now 1
y = x # true, the variable `y` is equal to 1
y = x # true, the variable `y` is equal to variable `x`
x = 1 # true, `x` is now 1, `y` is also 1Unification is a process for helping you solve those equations. Given x=1 and y=x what is y? Well, obviously it’s 1 . That’s what unification is doing.
Logic Programming in Polar
Putting the two together — rule inference and unification — you end up with a logic engine that can make simple deductions:
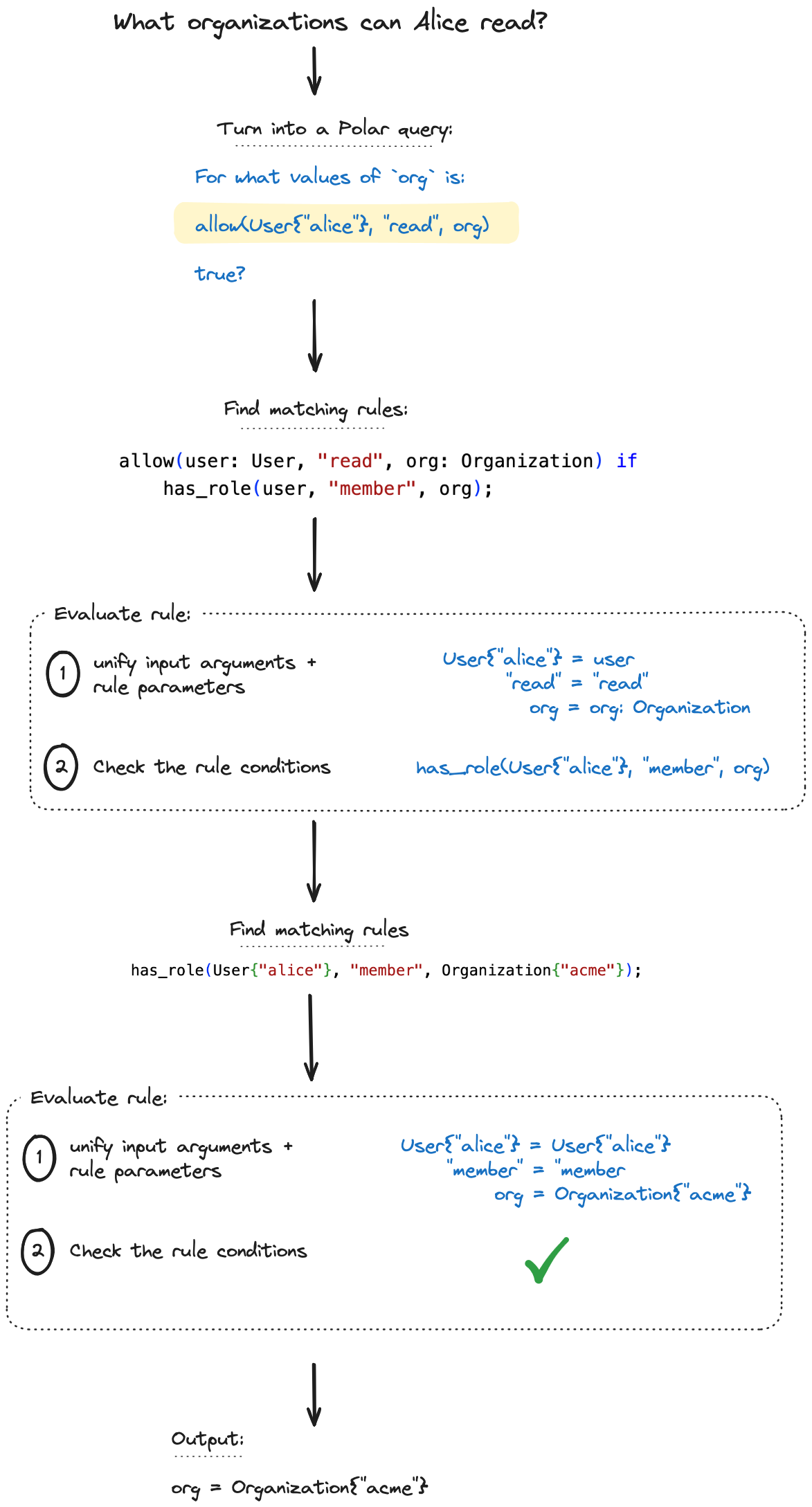
Querying a Polar policy
Here’s an example of how you query a policy using the oso-cloud CLI:
> tee -a intro.polar <<EOF
allow(user: User, "read", org: Organization) if
has_role(user, "member", org);
has_role(User{"alice"}, "member", Organization{"acme"});
EOF
> oso-cloud policy intro.polar
Policy successfully loaded.
> oso-cloud query allow User:alice read Organization:_
allow(User:alice, String:read, Organization:acme)The output of oso-cloud query is showing the result of logical deductions: it “filled in” the missing argument of Organization:acme.
And you can extend this:
> tee intro.polar <<EOF
allow(user: User, "read", org: Organization) if
has_role(user, "member", org);
has_role(User{"alice"}, "member", Organization{"acme"});
has_role(User{"bob"}, "member", Organization{"megacorp"});
EOF
> oso-cloud policy intro.polar && oso-cloud query allow User:_ _ Organization:_
Policy successfully loaded.
allow(User:alice, String:read, Organization:acme)
allow(User:bob, String:read, Organization:megacorp)This time there’s an additional fact — user bob is a member of megacorp.
And the query is even more generic — what are all the users, with any permission, on any organization. Using the same deduction process as above, Oso Cloud determines that alice can read acme and bob can read megacorp.
There’s a particularly nice element of logic languages on display here: you use the exact same declarative configuration to answer “can Alice read Organization:acme” as well as “what are all the organizations Alice can access”. Which is exactly what you need for common authorization use cases.
Using Inference to Remove Redundancy
Now suppose you introduce more roles and more permissions by defining a member with the following permissions:
allow(user: User, "read", org: Organization) if
has_role(user, "member", org);
allow(user: User, "create_repository", org: Organization) if
has_role(user, "member", org);And an admin with a slightly increased set of permissions:
allow(user: User, "read", org: Organization) if
has_role(user, "admin", org);
allow(user: User, "create_repository", org: Organization) if
has_role(user, "admin", org);
allow(user: User, "invite_users", org: Organization) if
has_role(user, "admin", org);You can see that it starts to get a little repetitive. And so you can write logic wherever it makes sense to remove redundancy. In the above case, admins can do whatever members can do, so for the admin permissions you can write:
- allow(user: User, "read", org: Organization) if
- has_role(user, "admin", org);
-
- allow(user: User, "create_repository", org: Organization) if
- has_role(user, "admin", org);
+ has_role(user: User, "member", org: Organization) if
+ has_role(user, "admin", org);
allow(user: User, "invite_users", org: Organization) if
has_role(user, "admin", org);
That is, you use inference logic to say that a user has the “member” role at an organization if they have the “admin” role. Rule inference logic is recursive. By adding that one rule, you now know that any rule that relies on a user being a member of an organization will also work for a user who is an admin of the organization. This saves you from needing to repeat all the member permissions on the admin – and from needing to remember to do that every time you add a new permission to members.
Incidentally, the above use case is so common that Polar has some built-in primitives to express it. You would write it as:
actor User { }
resource Organization {
roles = ["admin", "member"];
permissions = ["read", "create_repository", "invite_users"];
"read" if "member";
"create_repository" if "member";
"member" if "admin";
"invite_users" if "admin";
}which is a little less noisy, while also baking in validation logic to prevent typos of names.
Under the hood those "read" if "member" rules expand to the same thing you wrote earlier
# "read" if
# \/
has_permission(user: User, "read", organization: Organization) if
# "member" ;
# \/
has_role(user, "member", organization);it’s purely syntactic sugar.
Pulling it all Together
Coming back to the GitHub example, the full logic from earlier would look something like:
actor User {}
resource Organization {
roles = ["member", "admin"];
}
resource Repository {
roles = ["reader", "triage", "admin"];
permissions = ["close_issues"];
relations = {
parent: Organization,
};
"admin" if "admin" on "parent";
"close_issues" if "triage";
"triage" if "admin";
}
has_role(user: User, role: String, repository: Repository) if
org matches Organization and
has_relation(repository, "parent", org) and
has_role(user, "member", org) and
default_repository_role(org, role);
resource Issue {
permissions = ["read", "close"];
relations = {
parent: Repository,
creator: User,
};
"close" if "creator" and "read" on "parent";
"close" if "close_issues" on "parent";
}
has_permission(user: User, "close_issues", repository: Repository) if
org matches Organization and
has_relation(repository, "parent", org) and
role matches CustomRole and
has_relation(role, "parent", org) and
has_role(user, role, repository) and
grants_permission(role, "Repository", "close_issues");
grants_permission(role: Role, resource_type: String, permission: String) if
inherited_role matches String and
inherits_role(role, inherited_role) and
grants_permission(inherited_role, resource_type, permission);In this policy there are effectively five different ways (not counting the combinatorial explosions of all of them) that a user might get permission to close an issue:
- They are the issue creator, and they have read-access on the repository
- They directly have an appropriate role (e.g. “triage”) on the repository it belongs to
- They directly have a custom role on the repository, and the organization configured that role to have “close_issues” permission on repositories
- They are a member of the organization, and the organization configures members to have at least “triage” level access on all repositories
- They are an organization admin which grants them admin-level access on all repositories.
Phew!
What makes logic programming a powerful paradigm for authorization is the ability to implement this kind of branching conditional logic, which you typically see in authorization systems, with reusable logical predicates (i.e., more rules). Polar’s logic programming foundations let it represent this logic clearly and concisely.
What’s more, by pulling the authorization logic out of the individual services and into a common location, multiple teams can collaborate on the policy. Because the policy language is declarative, the rules are easy to read and the logic is easy to understand, further facilitating collaboration.
For example, to extend the prior policy to make “closing locked issues” a distinct permission, you can make a small policy change:
resource Issue {
permissions = ["read", "close"];
relations = {
parent: Repository,
creator: User,
};
- "close" if "creator" and "read" on "parent";
- "close" if "close_issues" on "parent";
+ "close" if "creator" and "read" on "parent" and is_locked(resource, false);
+ "close" if "close_issues" on "parent" and is_locked(resource, false);
+ "close" if "close_locked_issues" on "parent";
}From Logic to Data: Facts as SQL
Expressing authorization logic in a language like Polar is half the battle. What it gives you is a consistent approach to writing reusable authorization logic that multiple teams can collaborate on building.
However, we’ve been deliberately skipping over data: where it comes from and how it affects performance.
Earlier, we showed how you can add data by writing facts directly in the policy:
has_role(User{"alice"}, "member", Organization{"acme"});From the logic programming standpoint, there’s nothing inherently wrong with this. There’s no real need to make a distinction between rules and facts — remember, a fact is just an unconditionally true rule. It’s down to the implementation to provide convenient APIs for modifying the state of our system by adding/removing new facts, and to implement an efficient way to store/index/lookup facts.
Storing facts
Datalog illustrates this nicely. Datalog is a logic programming language that distinguishes rules from facts as a fundamental element of its design. One way that different implementations of Datalog are distinguished from one another is the strategies they use for evaluating rules and facts together in optimal ways: https://en.wikipedia.org/wiki/Datalog#Evaluation.
In fact, we could have used Datalog to achieve our data goals — but that would mean we have to build our own Datalog implementation, backing data store, etc. We don’t want to do that.
We want to leverage existing tried and true technology — like SQL. And more specifically, SQLite.
And so what we decided was: we should have a custom data model purpose-built for Polar and backed by SQL. We’ve been through a few iterations of said data model, and landed on a painfully simple one: we store facts as rows in SQL tables.
Initially we put all facts with the same arity (number of arguments) in one table together. But we realized that with SQLite we would be better served by dynamically creating tables for a given fact type, which we defined as the fact name (e.g. “has_role”) and argument types.
In Polar, values are either raw primitives (strings, integers, booleans), or type + ID pairs, like { type: "Organization", id: "acme" }. And we can represent primitives in that format too (e.g. { type: “String”, id: “member”}).
Where this leaves us - for a fact like:
has_role(User{"alice"}, "member", Organization{"acme"});we create an entry in a fact index, which maps an incrementing ID to the fact type, e.g.
1 -> has_role, [User, String, Organization]and then store the id: portions of the fact value (i.e. the quoted parts) in the fact_1 table:
arg0 | arg1 | arg2
---------------------
alice | member | acmeRetrieving Facts
So now the question becomes: how should Polar access this data? There are two options worth considering:
- Make it possible to access the backing datastore as part of query evaluation.
- Split evaluation into two phases: query evaluation, and data lookups
We ultimately opted for (2) because we knew when we started that we were heading towards something that could support data split across multiple services, so we would need those two steps to be separated.
How this works is: when Polar evaluates a query like allow User:alice read Organization:_, it works mostly like a regular logic programming language. It performs unification and applies inference logic to find all possibilities of what the input variables could be – with one important difference.
When Polar sees a condition like:
has_role(user, "member", organization)It considers two distinct possibilities:
- The condition is satisfied by some other rule, and so should find matching rules and evaluate those
- The condition is satisfied by a concrete fact that is stored in the underlying database. In which case, track this in its internal state as something to be resolved later.
And so instead of Polar returning concrete results like before, Polar is actually returning an intermediate representation of all the ways the query could be satisfied using facts in the database.
For the above example rule of “users can close issues if they have the ‘triage’ role on the repository it belongs to”, asking the query “which issues can Alice close” results in the intermediate representation:
Outputs:
issue: f0.arg0
Facts:
f0: has_relation(Issue, String, Repository)
f1: has_role(User, String, Repository)
Conditions:
f0.arg2 = f1.arg2
f0.arg1 = "parent"
f1.arg1 = "triage"
f1.arg0 = User{"alice"}It’s no coincidence that this looks a lot like SQL’s SELECT ... FROM ... WHERE syntax. The final step in this process is to turn the above into SQL, and query our embedded SQLite database.
For the facts, indexed f0 and f1 , we look up the corresponding fact tables via the index. For simplicity, I’ll assume those tables are fact_0 and fact_1 . The SQL output is:
SELECT f0.arg0
FROM
fact_0 f0,
fact_1 f1
WHERE
f0.arg2 = f1.arg2 and
f0.arg1 = 'parent' and
f1.arg1 = 'triage' and
f1.arg0 = 'alice';Interlude: Performance
Given that one of the motivations for using SQL was performance, how well does this perform?
Because our facts are in SQL tables, we can generate a bunch of indexes for those tables using simple heuristics:
CREATE UNIQUE INDEX fact_0_idx_0 on fact_0 ( arg0, arg2, arg1 );
CREATE UNIQUE INDEX fact_0_idx_1 on fact_0 ( arg2, arg0, arg1 );
CREATE UNIQUE INDEX fact_1_idx_0 on fact_1 ( arg0, arg2, arg1 );
CREATE UNIQUE INDEX fact_1_idx_1 on fact_1 ( arg2, arg0, arg1 );Our SQL queries end up being a number of joins, and simple filters on these indexed columns. This makes the SQLite query planner very happy:
QUERY PLAN
|--SEARCH f0 USING COVERING INDEX fact_0_idx_0 (arg0=?)
`--SEARCH f1 USING COVERING INDEX fact_1_idx_1 (arg2=?)It does exactly what you would expect: it finds all of the repositories that alice is has the “triage” role for, and then gets all of the issues belonging to those repositories.
And in the case where we ask if alice can close a specific issue? The SQLite query planner is smart enough to realize that issues belong to strictly one repository, whereas users might have roles on many repositories and reverses the ordering of the joins:
QUERY PLAN
|--SEARCH f1 USING COVERING INDEX fact_1_idx_0 (arg0=?)
`--SEARCH f0 USING COVERING INDEX fact_0_idx_0 (arg0=?)Polar + Facts: An Ideal Combination
At this point I’m basically just explaining to you why SQL is cool…But it’s hard to overstate how nice it is for us to be able to focus purely on providing good inputs to a battle-tested SQL engine like SQLite rather than attempt to build this. We get to spend our innovation tokens elsewhere.
We’ve also drawn a relatively clear line in the sand. Polar supports:
- Common authorization data: roles, relationships, attributes
- Custom data types expressed as facts
- Arbitrary combinations of facts expressed via
andandor - A handful of comparisons like integer comparisons, and time-based checks (for expiration).
- Recursive data lookups (e.g. files and folders hierarchies a la Google Drive).
We think this the ideal combination: flexible enough to represent almost anything, while being structured enough for us to write a robust querying layer using SQLite to do the underlying query planning and data lookups.
Looking back, it’s unsurprising that SQL works so well in a Datalog-like logic programming language. SQL was itself inspired by logic programming, and Datalog is frequently described as a stepping stone between logic programming and relational algebra. Everything starts blurring together the more you look at it.
Distributing Queries
With Polar we have a declarative way to express authorization logic. And we’ve seen that we can use Polar with a custom data model in SQL to evaluate queries fast. We use that to build our central authorization system (Oso Cloud).
Returning to our IssuesService example: if we want to use that central authorization system to decide “can Alice close issue #42”, we’ll need to give it access to the data it needs somehow.
Typically, centralized authorization systems – including Oso Cloud – have achieved this by requiring that any necessary data exist in the authorization system at the time the decision is made. This means either:
- Duplicating authorization-relevant data between the application and the authorization service
- Moving to event sourcing
Both of those sound like a lot of extra work just to answer some authorization questions. In the case of duplicating the data, you’re either building a replication process or you’re passing extra data over the wire for every authorization request. If you move to event sourcing, then you’re taking on a major application refactor.
However you choose to get the data into the service, some operations will also return a long list of data back out of it. Think back to the case where we asked for all the issues that Alice can close. If Alice has access to hundreds of issues, then the response will include all of them, increasing latency.
This led us to consider a different option: distribute the authorization. We can centralize anything that’s shared across multiple services and leave everything else in the application.
For example, in the GitHub example most of a user’s permissions on an issue come from the repository roles, and so one path to implement it would be:
// issuesService/controller/closeIssue.ts
async function closeIssue(currentUser: User, issueData: IssueData) {
// Note: we should still check for read permission on the repo
// even if the user is the creator -- you cannot
// close issues for repositories you don't have access to
if (!canRead) {
throw new PermissionDeniedError();
}
if (!canClose) {
// Implement issue-level authorization logic directly in the issue service.
//
// unless you have the repository-level canClose permission,
// you need to be the issue creator
const issueCreator = await db
.selectFrom("issue")
.select("creator_id")
.where("id", "=", issueData.id)
.execute();
if (issueCreator[0] !== currentUser.id) {
throw new PermissionDeniedError();
}
}
// close the issue
}
Which, to be frank, is not too bad at all. Most of GitHub runs off of what organization/repository permissions a user has, so you manage that logic and data in the shared authorization service. But you implement domain-specific authorization logic, like “issue creators can close their own issues”, within the service (i.e. IssueService) and use the application data you already have.
But we can do better. The above code has one big downside: a significant amount of authorization logic has bled into the IssuesService.
That’s bad because it creates a coupling between the AuthzService and the IssuesService.
Suppose you want to modify your authorization logic to differentiate between which users can close locked issues. That might look something like:
- Add code to IssuesService for checking if the user has
"close_locked_issues"permission. Deploy these changes behind a feature flag. - Add the new permission to roles in the AuthzService, redeploy these changes.
- Toggle the feature flag for IssuesService to enable the new feature.
Small changes in one service require coordinating code changes across multiple services (and therefore teams).
At the same time, by deferring domain-specific authorization to the associated services, each team is left to “draw the rest of the owl” in their application. For example, it’s fortunate that when implementing “creators can close issues”, the Issues team remembered to check the issue creator still has read-level access to the repository (employees who left the company shouldn’t be able to close their old issues). But this logic is outside the AuthzService, so you’ve lost most of your tools to make sure that this line is implemented correctly, and tested.
Cleaning up the Mess
As we said at the beginning: authorization is messy.
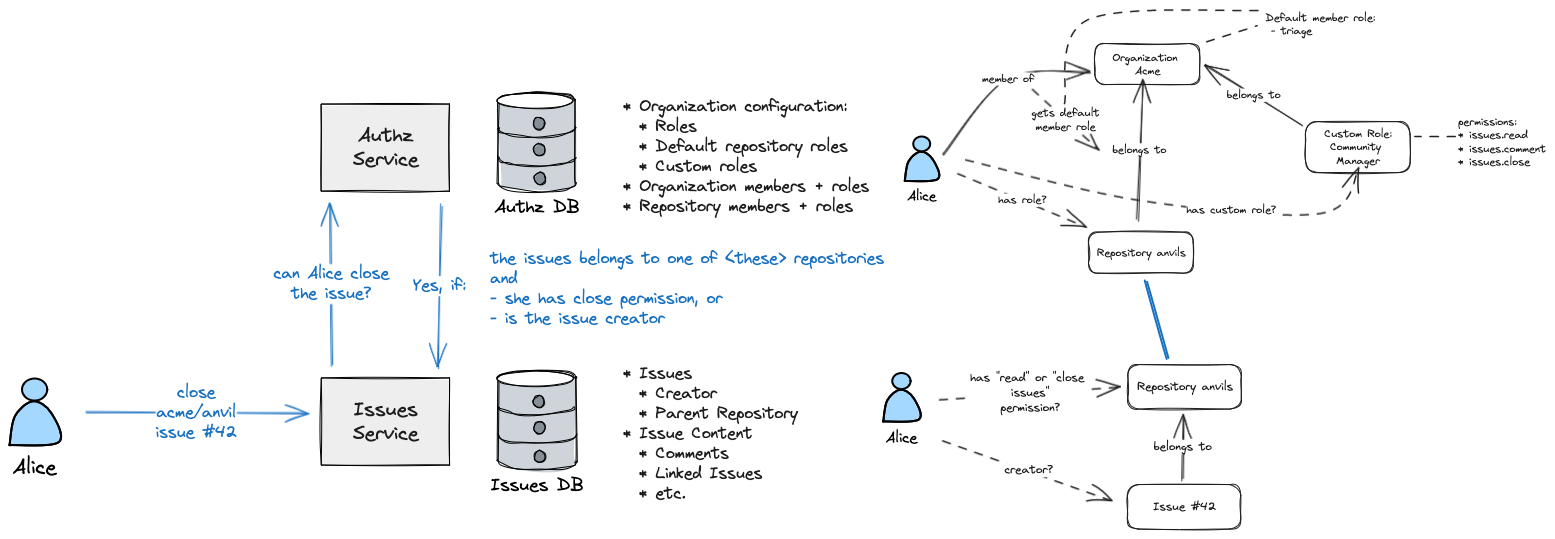
To decide who can do what to which resources, you need knowledge about what those resources are and how they relate to other resources. But you don’t want authorization logic to leak into your application, and you don’t want to duplicate application data in your authorization service. That means you need a way to distribute authorization decisions across both the AuthzService and IssueService.
The code sample above got us close, but a solution that eliminates the leaked authorization logic while maintaining encapsulation of the domain-specific data would be more resilient to changes in logic or data on either end. Practically, this means:
- Centralizing all authorization logic in the authorization service
- Centralizing shared authorization data (e.g. organization and repository roles) in the authorization service
- Keeping domain specific authorization data in the appropriate application database
Evaluating Polar against an Application DB
We achieve this by bringing the power of Polar to data stored across multiple data stores. And importantly, to data stored outside of Oso Cloud.
We have prior experience turning Polar into SQL that runs inside an application. However, previously we relied on ORMs to do the query building. We returned an intermediate representation inspired by relational algebra, and used the ORM to turn this into SQL.
But given that we are already working with an intermediate representation we know is flexible enough to convert to SQL, we looked at what we already had when thinking about this problem again.
We need to do two things:
- Turn our intermediate representation into SQL to run it against an application database.
- Split the intermediate representation into an Oso part that runs centrally and a local part that runs in the application.
One way to do (1) which is relatively naive, but close to what we need, is to use CTEs to make the application database “look like” our own internal schema, e.g. in the previous query replace fact_0 and fact_1 with a CTE describing how to get that data:
WITH fact_0(arg0, arg1, arg2) as (
SELECT id, 'parent', repository_id FROM
issues
), fact_1(arg0, arg1, arg2) as )
SELECT user_id, "role", repository_id FROM
repository_roles
)
SELECT f0.arg0
FROM
fact_0 f0,
fact_1 f1
WHERE
f0.arg2 = f1.arg2 and
f0.arg1 = 'parent' and
f1.arg1 = 'triage' and
f1.arg0 = 'alice';To get this, we just need a configuration file that maps between the Oso data schema and SQL tables, e.g.
facts:
has_relation(Issue:_, String:_, Repository:_):
query: |-
SELECT id, 'parent', repository_id FROM
issues
has_role(User:_, String:_, Repository:_):
query: |-
SELECT user_id, "role", repository_id FROM
repository_rolesHaving a simple mapping from an application DB to Oso facts was no accident. We have a simple rule of thumb for mapping data to Oso:
- Roles: many-to-many or one-to-many tables which relate two tables/primary keys and have an additional “role” attribute.
- Relationships: a primary key + a foreign key
- Attributes: a primary key + a column value
We tell our customers to use this simple mapping for sending Oso data, and so all of our common patterns for authorization rules are expressed in terms of this data.
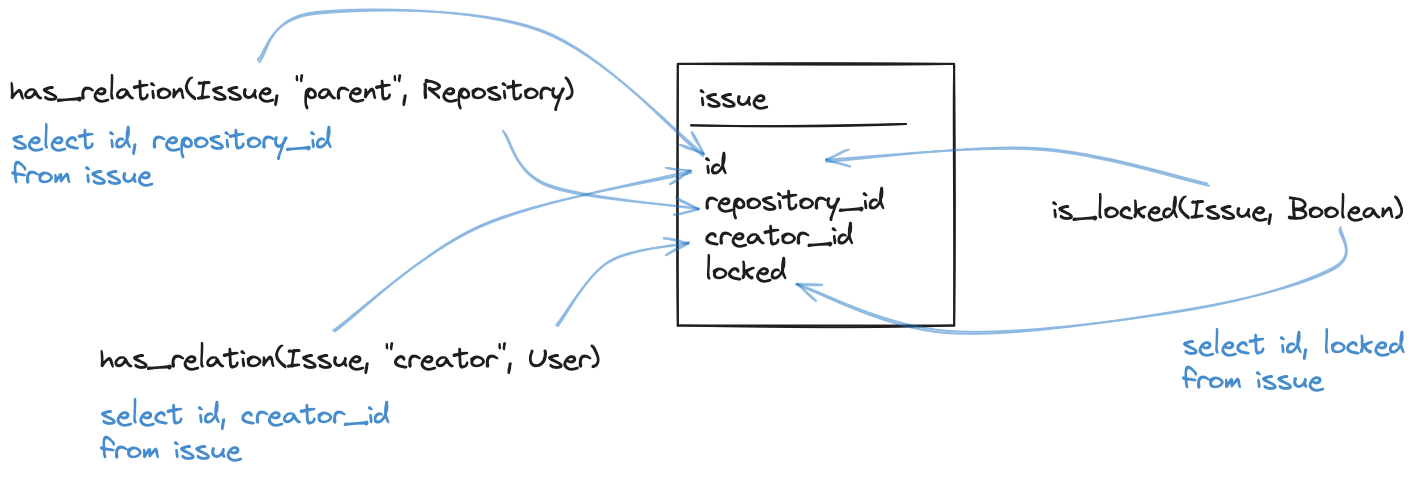
The mapping that we create is a “virtual” mapping. We don’t actually need to modify the database in any way, nor persist any data. But if we were to convert the data into how Polar sees it, or to expand out the CTEs that we generate into actual tables, it would look something like this:
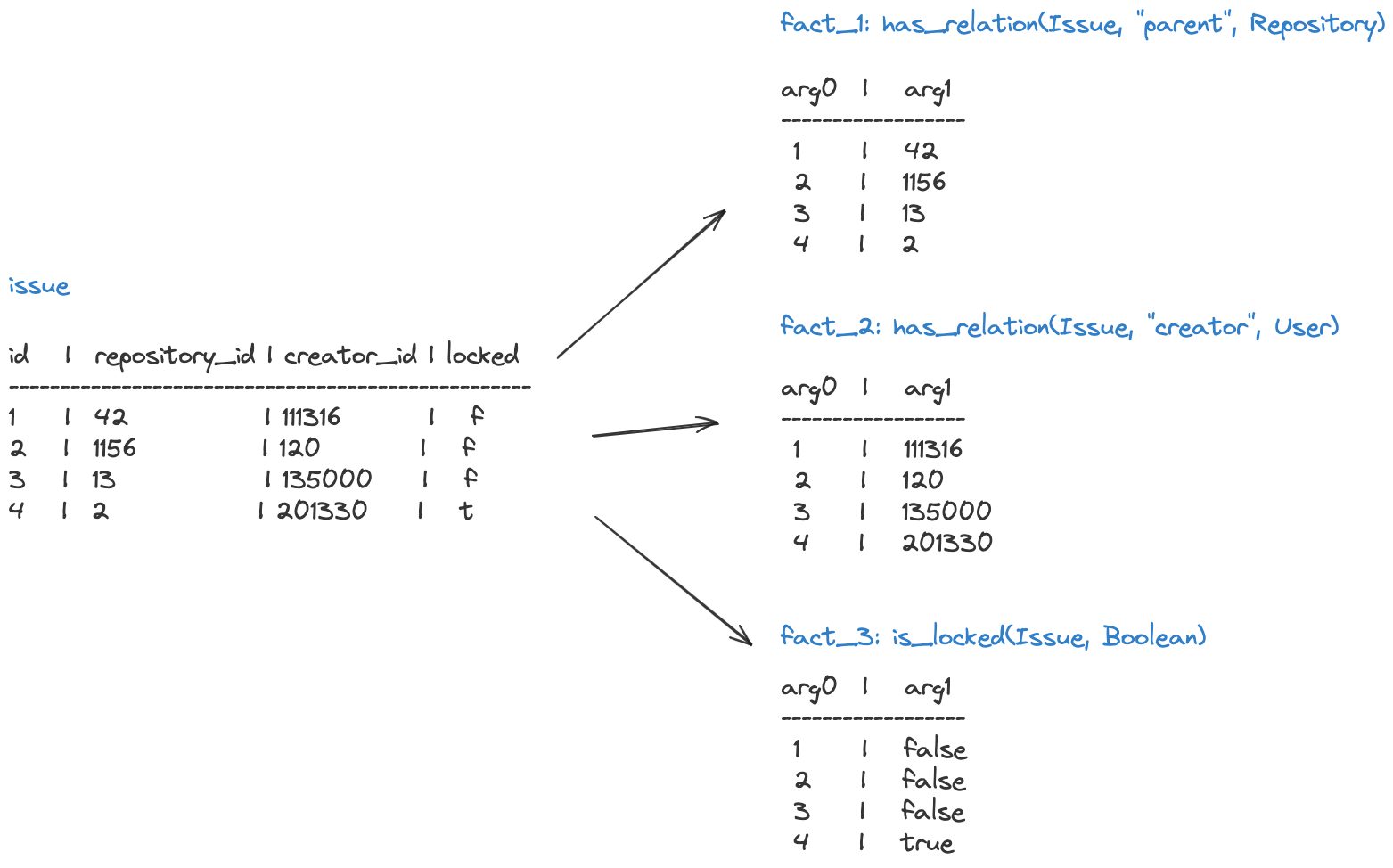
And just like that* we have a policy language that can run over an application database with minimal configuration.
*Note: I would like to clarify that the intent here is to say that it’s that easy for Oso users, and not diminish the effort of the Oso team who implemented this feature 🐻
Splitting the lookup across two services
We now have (1) — a way to run SQL against an application database.
Lets move on to (2) — split the intermediate representation into an Oso part and a local part.
Once we had figured out the configuration and how that would compile to SQL, deciding on how to “split” the intermediate state was clear.
We partition the facts we’re searching for into Oso parts and local parts, and create dummy variables to bridge the two, e.g. we know the issuesService manages issue data, and therefore the has_relation facts between issues and repositories, whereas Oso manages roles
Before splitting:
Outputs:
issue: f0.arg0
Facts:
f0: has_relation(Issue, String, Repository)
f1: has_role(User, String, Repository)
Conditions:
f0.arg2 = f1.arg2
f0.arg1 = "parent"
f1.arg1 = "triage"
f1.arg0 = User{"alice"}
After splitting:
### Oso part:
Outputs:
var0: f1.arg2
Facts:
f1: has_role(User, String, Repository)
Conditions:
f1.arg1 = "triage"
f1.arg0 = User{"alice"}
### Local part
Outputs:
issue: f0.arg0
Facts:
f0: has_relation(Issue, String, Repository)
Conditions:
f0.arg2 = inputs.var0
f0.arg1 = "parent"On Oso’s side, we evaluate the Oso part in an identical way to before: we compile it to SQL, run the SQL, and get back a set of results.
To resolve the rest of the authorization result within the application, we’ll need to take:
- The other half of the intermediate representation
- The schema mapping configuration
- The partially evaluated results from Oso
And turn them into a SQL query we can run.
That is, we combine:
the required lookups:
Outputs:
issue: f0.arg0
Facts:
f0: has_relation(Issue, String, Repository)
Conditions:
f0.arg2 = inputs.var0
f0.arg1 = "parent"plus the configuration:
has_relation(Issue:_, String:_, Repository:_):
query: |
select id, repository_id from issuesand the inputs from Oso:
inputs: ('anvil', ...)to compute the SQL to perform “the rest of the authorization”:
WITH fact_0(arg0, arg1, arg2) as (
SELECT id, 'parent', repository_id FROM
issues
)
SELECT f0.arg0
FROM
fact_0 f0
WHERE
f0.arg2 in ('anvil', ...);The IssueService can run this SQL against its own database to check authorization of a single entity:
// get "Local Part" from Oso Cloud
const authorizeSql = await oso.authorizeLocal(user, "close", issue);
const { allowed } = (
// evaluate "Local Part" against application database
await sql.raw<{ allowed: boolean }>(authorizeSql).execute(db)
).rows[0];By converting the intermediate polar representation to SQL that the IssueService can run, we have built a way to access authorization data that is distributed across multiple services.
With all this in place, the closeIssue method gets a whole lot shorter:
async function closeIssue(issueData: IssueData) {
// get "Local Part" from Oso Cloud
const authorizeSql = await oso.authorizeLocal(user, "close", issue);
const { allowed } = (
// evaluate "Local Part" against application database
await sql.raw<{ allowed: boolean }>(authorizeSql).execute(db)
).rows[0];
if (!allowed) {
throw new PermissionDeniedError();
}
// close the issue
}
You can also use this approach to generate lists of authorized issues. For example, to return all the issues that the current user can close:
// get "Local Part" from Oso Cloud
const listSql = await await oso.listLocal(user, "close", "Issue", "id")
// evaluate "Local Part" against application database
const results = await db
.selectFrom("issues")
.where(sql.raw<boolean>(listSql))
.selectAll()
.execute();Because you’re creating the list against the local database, it’s easy to sort and paginate the results.
// get "Local Part" from Oso Cloud
const listSql = await await oso.listLocal(user, "close", "Issue", "id")
// evaluate "Local Part" against application database
const results = await db
.selectFrom("issues")
.where(sql.raw<boolean>(listSql))
.orderBy("created_at")
.offset(50)
.limit(25)
.selectAll()
.execute();
Conclusion
Referring back to our initial criteria:
a shared authorization capability must provide mechanisms for:
- expressing the above logic, which spans the Authz and Issues domains
- using data stored in both the AuthzService and IssuesService
- supporting yes/no questions as well as more flexible “list” questions
We achieved all three of these! We have Polar to express declarative logic decoupled from any one service. We distribute Polar across services to avoid needing to sync data anywhere, and our approach of compiling Polar to SQL makes it possible to ask any kind of question without needing to rewrite any logic.
Try it out here: https://www.osohq.com/docs/guides/integrate/filter-lists#list-filtering-with-decentralized-data
