
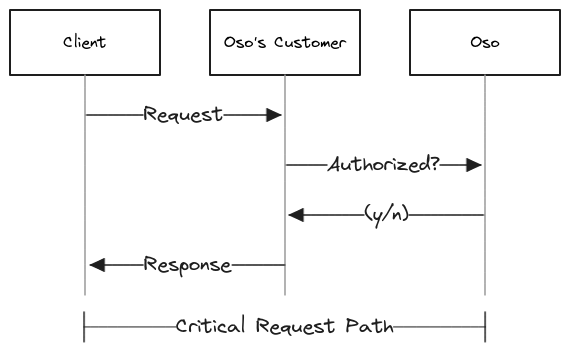
As engineers at Oso, we are acutely aware that being an authorization service provider puts us in the critical request path for our users. If we are slow, our users are slow. If we go down, our users go down. This means it is extremely important that we provide two things: fast response times and high availability.
But Oso is a startup. We don’t have an army of engineers waiting in the wings. So we can’t afford to build a lot of complicated custom infrastructure. We need to focus our energy on building Oso Cloud, not managing the infrastructure that supports it.
This means we need our infrastructure to be:
- Fast
- Reliable
- Low Maintenance
In this post, we’ll cover how we first achieved this with AWS Fargate, why that stopped working for us, and how that led us to ECS on EC2.
The Fargate Architecture
AWS Fargate is a managed service for deploying Docker containers. Our usage of AWS Fargate was a bit unusual, so it’s worth covering that first. This should also give you a sense of how our design constraints are very different from those of other companies.
We talked earlier about how the fact that we provide an authorization service means we need to pay particular attention to our reliability and latency. Those needs constrain the types of architectures that are viable, but there’s a very important fact about authorization data that plays in our favor: it’s not that big.
Ultimately, we just need to know whether to grant User:bob access to Repository:anvils. Nobody needs to store the 4K version of the Lord of the Rings Extended Edition in our database to do that (if you do, please reach out to us on Slack so we can help you with your authorization model!).
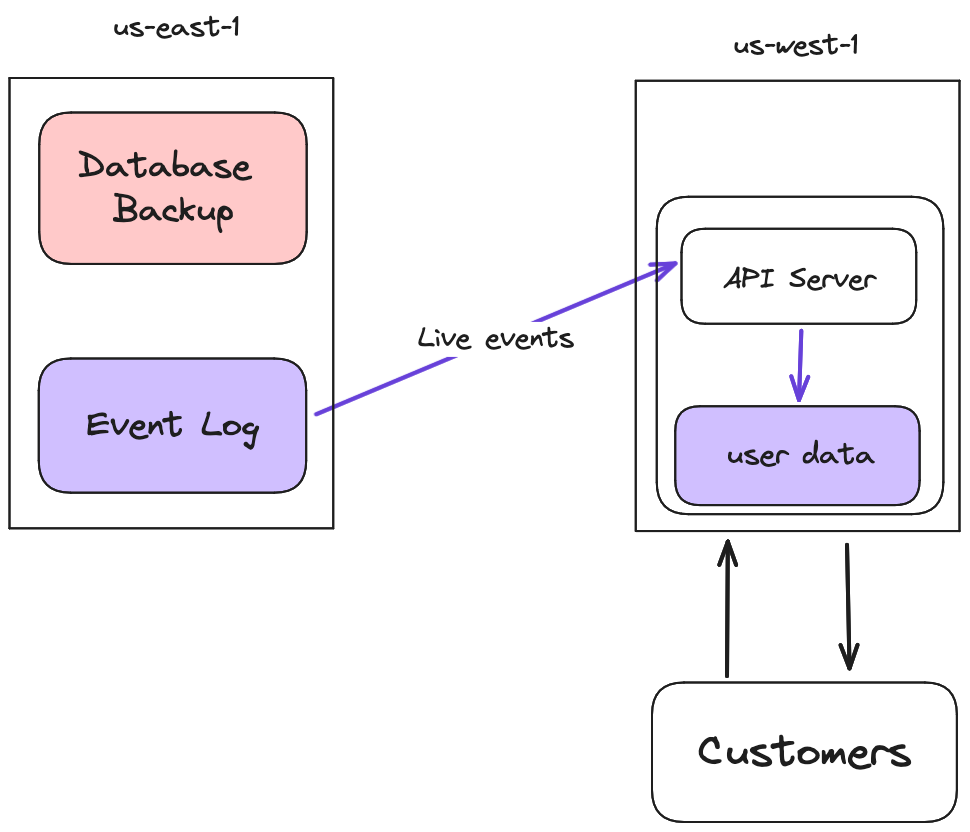
This was why we chose an architecture where we store data at the edge, in SQLite databases on volumes that are attached to our application servers. Every task (the ECS term for an application instance) in every region had a copy of our entire data set, and we used latency based DNS to route users to the closest region. In the end, our stack looked something like this:
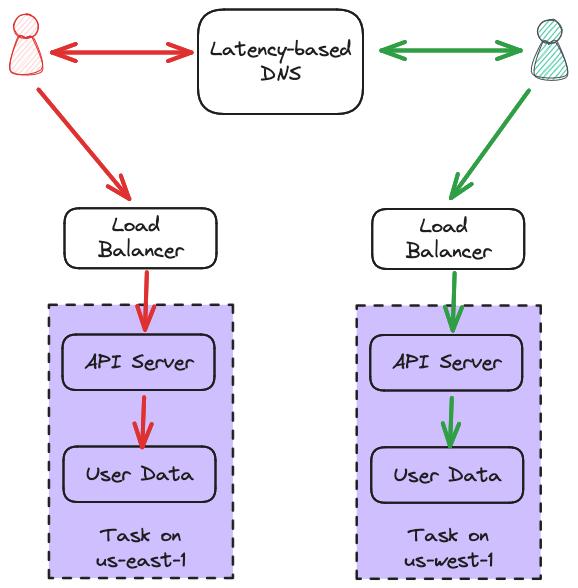
Not only was this stack fast and reliable, but it was absurdly simple. Each API Server had exclusive access to its data, so we didn’t need to worry about inter-task concurrency. Writes went to our central log (which you can read more about here), and were replicated to each task.
Because AWS Fargate is a managed service, it handled a lot of the infrastructure details for us and provided many useful management tools. This let us focus on building the application instead of dealing with infrastructure issues. Critically, Fargate made it straightforward for us to do zero-downtime deployments.
However, there was one major drawback to this architecture. Every time we started a new task (e.g. whenever we deployed new code), that task started with an empty data volume. So we had to re-sync our entire dataset from a backup and then wait for it to catch up to the latest writes before the new task could serve traffic. Otherwise, users would have seen stale reads. The process looked something like this:
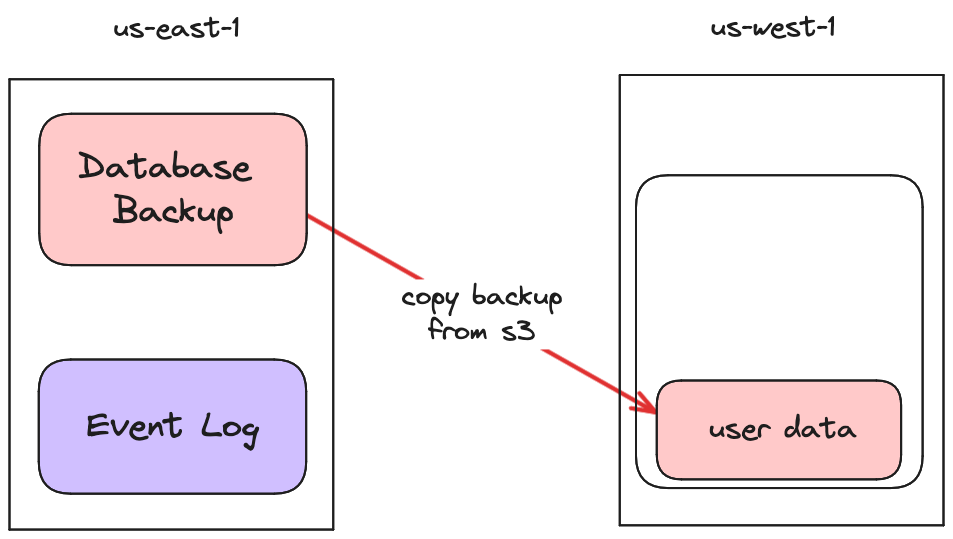
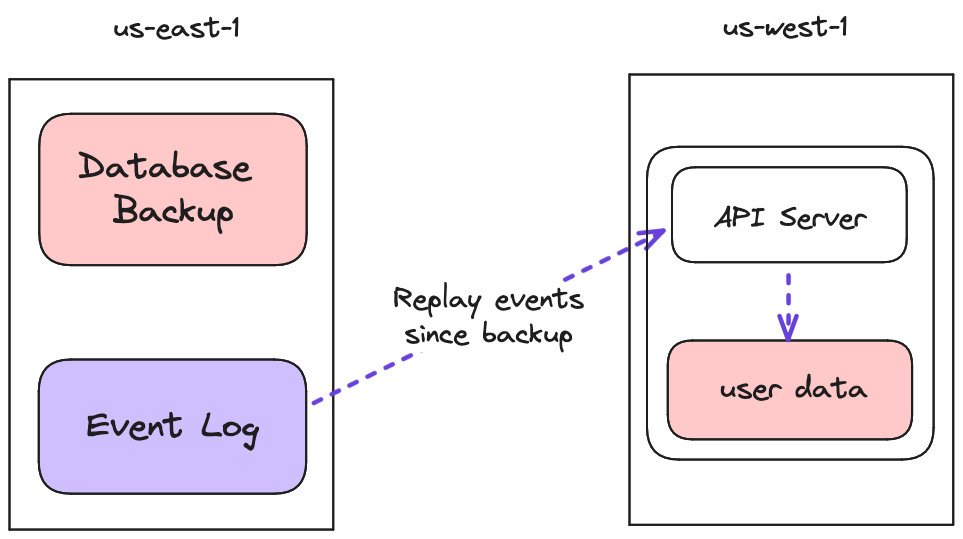
Because our dataset was small, we got away with this for a long time. It was fast and simple. We only had to pay the network transfer cost on startup, and we didn’t have to pay it on the request path.
Predictably, it didn’t work forever. As our dataset grew, moving data around became more expensive and every new service needed to pay this cost. Eventually, we reached a point where deploys took way too long, and we started to worry about time to recover from incidents during periods of high write load. Something had to change.
First Attempt: Shared Write Responsibility
Our solution to the initial sync problem was to decouple the database lifecycle from the service lifecycle. We would “front load” the sync costs by only restoring the data when we initialized the EC2 host that our tasks run on. This would allow us to restart the tasks quickly, because the data would already be on the host disk. To do this, we needed more control of the host than Fargate allows, but we wanted to preserve as much of the simplicity and ease of management of Fargate as we could. This is why we moved to ECS on EC2.
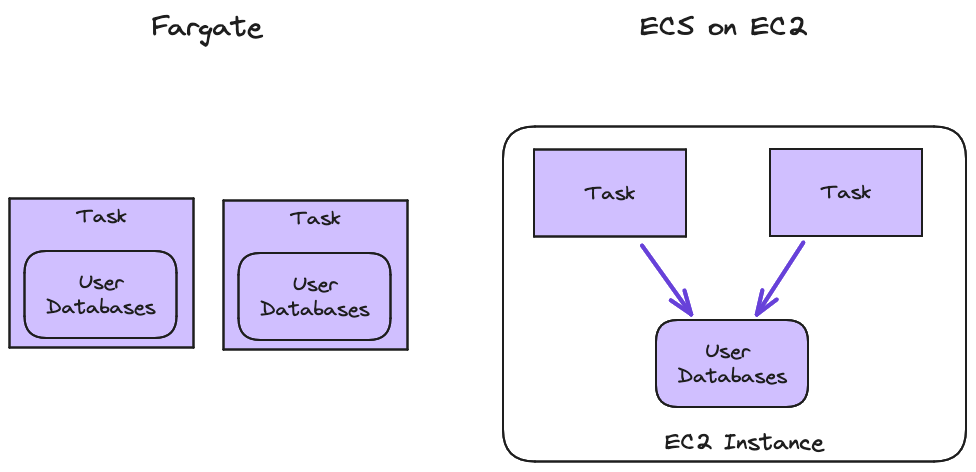
Here, it’s important to note some very nice properties of the ephemeral Fargate model:
- Every task had exclusive data access.
- Every task handled every write in exactly the same way.
- Data did not need to be durably persisted.
- No synchronization with other tasks was needed.
A lot of our code was written with these assumptions in mind. We didn’t have to have any special services. Every task was exactly the same. There was a nice symmetry there that made things easier to reason about.
We were hoping we could just lift and shift our app from Fargate to the new infrastructure without making any other invasive changes. So for our first attempt, that’s what we did. We continued to have each task look exactly the same, and handle both read and write operations. It looked something like this:
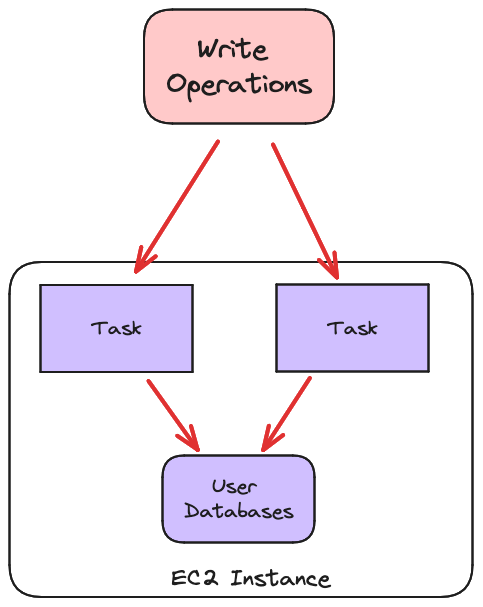
The details of this attempt are out of the scope of this post. Suffice it to say it was painful. Multiple readers are fine, but as soon as you have multiple writers you need to consider an explosion of different states the system could be in. We hadn’t had to consider those states before, so suddenly all those assumptions that were baked into our code started to break down.
We soon realized that even though we wanted to take the shortest path to our goal, just changing the infrastructure wasn’t enough. To get to the next viable state, we needed to go all the way and fully split up the read and the write paths in our code, too.
The Final Architecture: A Dedicated Writer
When we arrived on the final architecture, things clicked into place. By separating the read and write code paths, we were also able to decouple the read and write task deployment paths. Not only that, some amazing things happened. We started to have something that looked like a real “Storage Layer”, and our API Servers started to look a lot more like stateless containers.
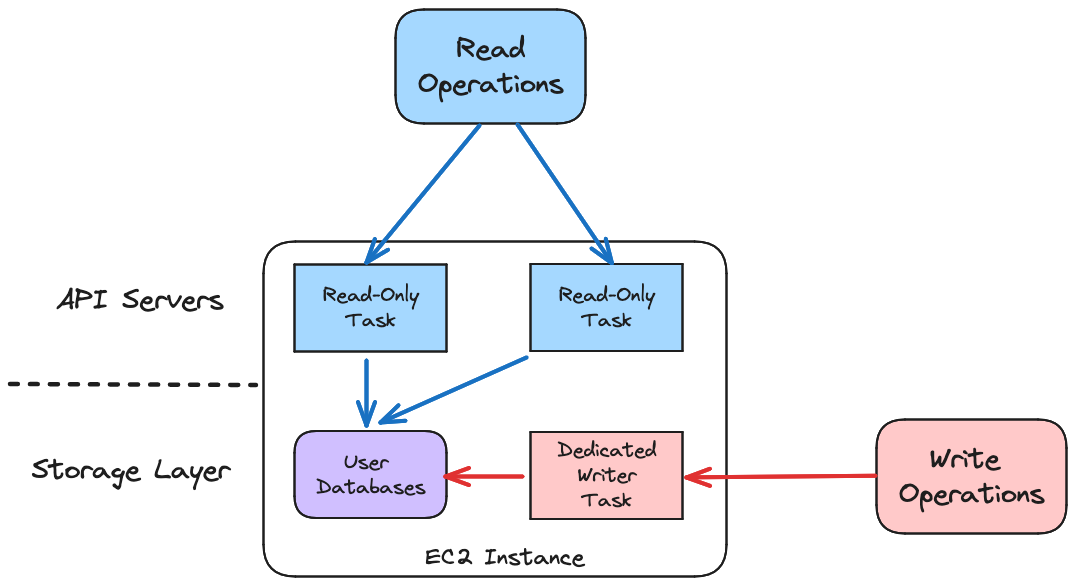
In this architecture, we’ve split the read and write responsibilities between two types of tasks. There’s a single dedicated writer task on each EC2 instance that handles all write operations. It does the initial database restore and updates the user databases as applications send us new authorization data. There are multiple read-only tasks that respond to all authorization queries from applications.
This alleviated our data synchronization problem. Now, instead of having to reinitialize the database every time we deploy the application, we only have to initialize it when we create a new EC2 instance.
Sadly, in letting go of Fargate, we also let go of our straightforward zero-downtime deployments. Now, we’ll talk about how we avoid downtime in this new system. With the read and write paths separated, we had to address downtime differently for each.
Avoiding Downtime: Writer Deployment
As we mentioned above, we introduced a single dedicated writer task on each instance that keeps databases up to date. This let us keep our write logic simple, but it also created a single point of failure on each EC2 host. Taking that task down for any period of time would mean that we’d stop updating the user databases, so readers on the same host would return stale data. This can lead to incorrect authorization responses.
Given that, upgrading the writer in place was not an option. To avoid downtime, we instead tied the lifecycle of the writer to the lifecycle of the host EC2 instance. This way, we never have any period where a reader serves traffic from data files that do not have a writer task keeping them up to date.
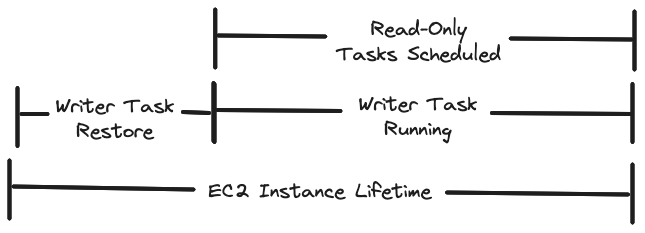
The way we actually coordinated these lifetimes and told the ECS scheduler what to schedule and when is a bit complicated, and we realized it was too much for this post. We may do a follow up post doing a deep dive on the ECS scheduler if there’s interest (let us know).
While the dedicated writer upgrade is a bit too much to cover in depth right now, the way we avoided downtime in the read path is too critical to skip. Even this one step took us deep into AWS behavior and edge cases. Let’s look at that next.
Avoiding Downtime: Draining Container Instances
On our Fargate-based architecture, avoiding downtime was relatively easy because ECS provides rolling deployments out of the box. The ECS scheduler handles draining tasks before terminating them, which basically means doing the following:
- Stop sending user traffic to the task.
- Wait for in flight requests to complete.
Once those are done, terminating the task shouldn’t cause any user facing errors.
The task-level ECS rolling deployments still worked fine after we moved to ECS on EC2, but we ran into problems when we needed to terminate the underlying EC2 instances. ECS has no way of knowing that an EC2 instance is about to be terminated, so it can’t do its normal draining process. This means traffic can be routed to an instance that is terminating, or an instance may shut down with unprocessed in-flight requests. All of this ends up causing down time.
We needed some way to tell ECS that it should gracefully drain and shut down all tasks on an instance so we could terminate it. Fortunately, such a thing does exist. We can drain container instances in ECS by making an API call. The instance is normally in an ACTIVE state, but when we drain it, the instance transitions to DRAINING, signaling to ECS that it should start gracefully draining all the tasks on that instance. Once the instance has no more running tasks, it transitions to DRAINED and we can safely terminate the instance.
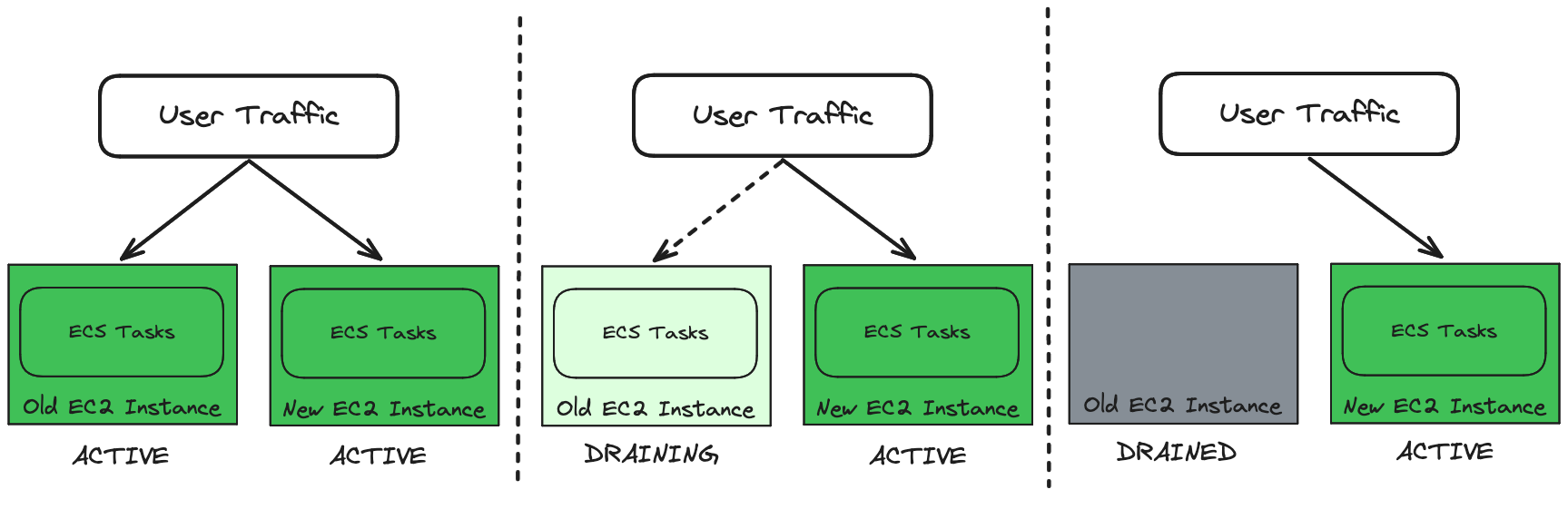
The ability to drain an instance is great, but this system would be completely unmanageable (and error prone) if we had to manually call this API every time we wanted to terminate an EC2 instance. We needed some way for this draining process to happen automatically, before the instance fully shut down.
The first thing we found is this approach that AWS recommends for automating container instance draining. The recommendation from that post is to use lifecycle hooks on the EC2 instances, so that whenever an instance is set to be terminated, AWS calls a lambda before completing the termination process. However, there is a very important caveat from the lifecycle hook documentation:
The result of the lifecycle hook can be either abandon or continue (…) If an instance is terminating, both abandon and continue allow the instance to terminate (…).
This means that there's no way to abandon termination of the instance if we detect that terminating the instance would cause downtime. As mentioned earlier, if Oso goes down, our customers go down, so this is a complete non starter for us.
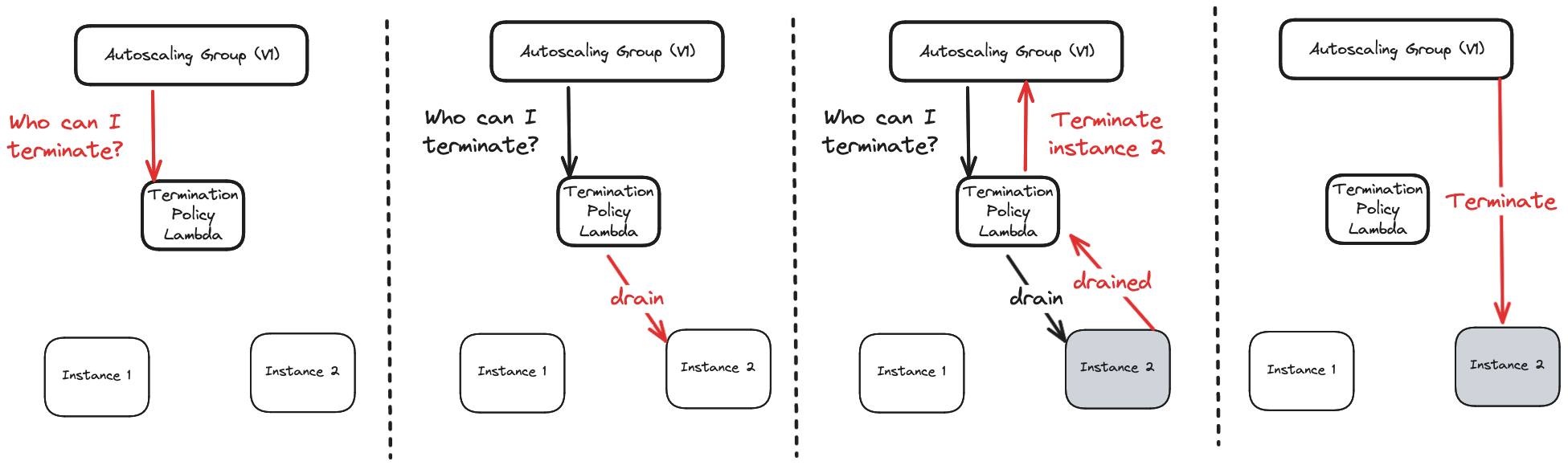
Fortunately, we deploy our EC2 instances in an EC2 Autoscaling Group (ASG). This gave us an out. When an ASG needs to terminate an instance for any reason, it uses a Termination Policy to choose the instance to terminate. The built in policies use simple heuristics, such as “oldest instance.” However, it’s also possible to implement a Custom Termination Policy using a lambda. This was exactly what we needed.
After creating and registering our termination policy lambda, the process for an ASG terminating an EC2 instance looked something like this:
- The ASG calls our lambda for suggested instances to terminate.
- The lambda calls the AWS API that triggers the draining process.
- The lambda returns the ID of the drained instance, or an empty list.
- If the list is empty, the ASG tries calling the lambda again.
- If the lambda returned an instance ID, the ASG knows it is safe to terminate that instance.
This system “fails closed”, in the sense that if anything goes wrong, it will default to not terminating the instance. With this system, we can confidently scale up and down and be sure that we won’t accidentally tear down infrastructure that we still need.
Conclusion
Our goal is to provide a service that solves the authorization problem, while also not completely burning ourselves out managing the infrastructure that supports it. The best way we’ve found to do that is to be ruthless about keeping things simple. We don’t rebuild things that already exist. At every opportunity we try to use the right tools and take advantage of their built-in features.
As Oso Cloud evolves to meet the needs of our growing community, we sometimes find that we’ve outgrown our architecture. When that happens, we have to be thoughtful about where we add complexity so we can keep our focus on building a great application.
Our new EC2-based architecture mitigated our initial sync problem while preserving much of the simplicity of the Fargate architecture that preceded it. We can now scale up without slowing down reader deployment. If we need to reduce writer deployment time in the future, we can do some tiered replication, or even potentially use EBS volume snapshots, but for now we don’t need that extra complexity. What we have is working for us.
Crucially, keeping things simple also amplifies the scope of what one engineer can contribute. We absolutely need this. The problems we’re trying to solve are not easy, and so that’s where our focus has to be. We can’t afford to waste anyone’s time fighting with over-engineered hand crafted systems.
Now that this migration is behind us, it’s feeling like we picked the right abstractions. We still have a relatively simple architecture, but separating the application layer and the storage layer has opened up some interesting possibilities. We’re thinking about preview environments, asynchronous background jobs on databases, better backup and restore functionality, and other crazier ideas.
If this sounds interesting you, we’d love to hear from you. Oso is hiring.