When we started building Oso Cloud, our managed authorization service, we didn’t know whether it would catch on. We met with hundreds of engineers as we built the Oso library, many of whom asked for the ability to offload authorization to a managed solution. But while we knew about internal projects like Google Zanzibar, a general purpose authorization service was an unproven idea.
We wanted to ensure that developers would accept the idea of decoupling authorization from their application in practice before we invested time in a full-fledged product. So the first version of Oso Cloud was a single service instance with a local SQLite database deployed on fly.io. We chose SQLite because it was battle-tested and its simplicity enabled us to spend less time worrying about our database backend and more time building the core product.
Fortunately for us, the product resonated with developers. Now that we knew the demand was real, we were presented with the problem of creating a highly available, low-latency service that we could sell. This is the story of how we successfully scaled from a single instance to a globally available service in 12 regions (and counting).
Requirements
Authorization sits on the critical path of most operations: any degradation to the authorization service degrades the overall application. As we started planning how to make our authorization service globally available, we agreed on the following requirements that reflect this reality:
- The system's availability should be at least 99.99%. This means that all service dependencies must have at least 99.99% availability.
- The round-trip latency, including network, for completing an authorization query should be under 10ms. This means we must deploy in the same region as our customers to minimize the cost of network latency.
- A customer should be able to access their environment from multiple regions. This means that if a customer deploys their application to
us-east-1andus-west-2, their data must be present in both regions to keep request latency under 10 ms.
In addition to these requirements, we also agreed on explicit near-term non-goals to help with making trade-offs in the design:
- We do not need to have high throughput for write requests for our first version. Our initial customers are business-to-business (B2B), so we expect a low volume of authorization data changes.
- Write requests do not need to be completed in under 10 ms. We expect human users to initiate authorization data changes, and thus, the write latency only needs to be fast enough not to degrade their user experience.
In short, reads need to be fast, wherever they happen and at any load. Writes can be a bit slower, because in practice they are ad-hoc procedures outside of the critical path.
Exploring our Options
At this point, we were confident that a general-purpose Authorization as a Service solution had merit, and we had a set of requirements for that service. Now we wanted to get something to market as soon as possible, in order to maximize the opportunity. That meant quickly moving from a single SQLite-backed instance to something that could handle production workloads at global scale. We considered several approaches, but quickly narrowed down to three proofs-of-concept that were most promising. In order to further optimize for speed, we prioritized using tested third-party components as-is wherever possible, rather than trying experimental approaches or forking projects.
Option 1: SQLite database replication
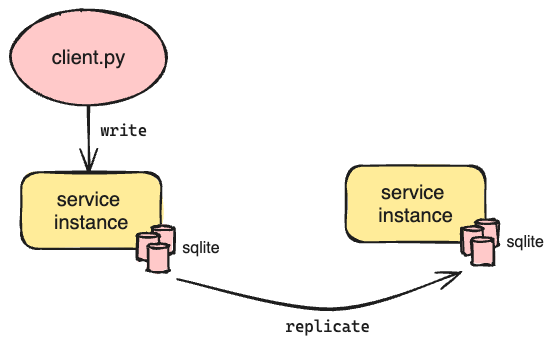
Our single service instance with SQLite already met our performance requirement. Having up-to-date replicas of SQLite would allow us to increase system availability by adding more redundancy. Additionally, because the services do not share resources, throughput would scale linearly with the number of services while keeping performance constant. But the simplicity of SQLite made database-level replication difficult. Each SQLite database is a collection of files (when using WAL mode) on disk. This makes the database portable, but because there’s no notion of a transaction log, it’s challenging to create database replicas without extra effort.
Today, there are several production-grade solutions for running SQLite in a distributed manner; LiteFS and Turso are two such current options. However, when we were building the system, these did not exist. We considered Litestream, the precursor to LiteFS, but its primary use case was backing up SQLite databases and not supporting live read replicas. We also considered Verneuil from Backtrace, but it is more suitable in cases where stale reads are tolerable, which does not apply to us. We ended up discarding this option due to these limitations.
Option 2: Highly-available Database
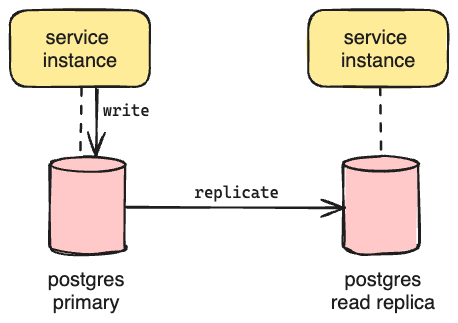
With SQLite database replication off the table, we investigated using a database that already provides first-class support for read replicas. A dedicated database layer would add a dependency to the system, but the managed solutions we evaluated provided availability Service Level Agreements (SLA) of 99.99% and exceeded them in practice, so they met our availability requirement. Since we deployed to AWS, we implemented a proof-of-concept to determine if Amazon Relational Database Service (RDS) for Postgres would meet our performance requirement. Postgres supports all the features we use in SQLite, so the code migration was straightforward. Unfortunately, even with the largest instance size, we could not achieve the same or better query performance as our local SQLite instance at a comparable load. We may have achieved parity with more time to investigate, but we were optimizing for speed of delivery, so we deferred further investment as a future exercise.
Option 3: Replicating Requests
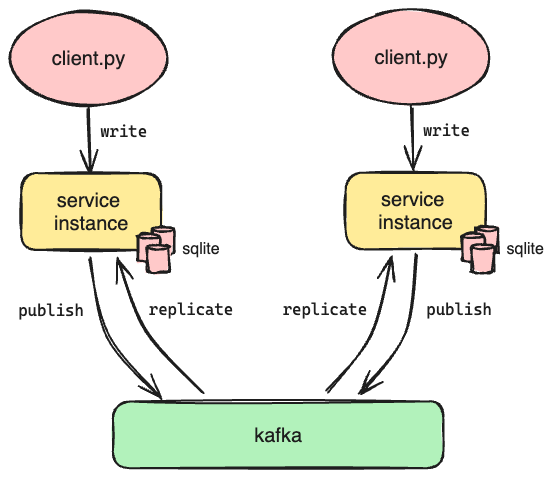
If we couldn’t replicate the database directly, perhaps we could replicate the requests to each instance of Oso Cloud instead. This would allow us to maintain identical databases for each of our instances of Oso Cloud, which is the same goal as Option 1. We already knew that met our performance requirements.
This is the architecture we selected. We considered a few approaches to distributing the requests. Ultimately, we determined we needed to add a new component to the architecture: some kind of message queue. Fortunately, there are many options to choose from. In the end we went with Apache Kafka.
Context: Oso Cloud’s Data Model
In this system architecture, multiple service instances accept write requests concurrently. Each write request is sent to Kafka to be replicated before it’s applied to the database. In a typical relational data model, this would introduce a risk that a database write fails because it violates integrity constraints. Fortunately, our data model has two key properties that allow us to do this safely:
- No logical constraints between tables
- All changes are idempotent
Let’s briefly look at the data model to see why this is the case.
Oso Cloud is a multi-tenant service. Each customer is a single tenant, and there can be many environments within each tenant. Each environment represents a unique instance of a customer's authorization service, so they can point their various Continuous Integration (CI) environments (e.g. QA, staging, or production) to dedicated configurations. Internally, we create a unique SQLite database for each environment to ensure the service only uses data from the requested environment in evaluating authorization queries.
The data we store in the database are called facts. For a fact like:
has_role(User{"alice"}, "member", Organization{"acme"});We create an entry in a fact index that maps an incrementing ID to the fact signature, e.g.:
id | predicate | arg_types
---+-----------+--------------------------
1 | has_role | User,String,Organizationand then store the data (i.e., the quoted parts) in a table that corresponds to the ID we just inserted (in this case, fact_1):
arg0 | arg1 | arg2
------+--------+------
alice | member | acmeThe data model doesn’t use any of the relational aspects of SQLite. There are no foreign keys - no fact depends on the existence of any other fact. The only constraint we care about is that each fact should exist exactly once, which we ensure by using INSERT OR IGNORE when we add new data so that duplicate insert attempts are silently ignored. As a result, we know that writes will never fail for ACID consistency violations, and that all operations are idempotent.
This model lets us safely use Kafka to replicate requests to all of our Oso Cloud service instances. Now let’s see how that works.
How we use Kafka
To explain how we use Kafka, we need to introduce some terminology.
Topic - A topic is a log of messages. In our case, the messages are write requests to Oso Cloud (e.g., fact inserts).
Partition - Kafka topics are divided into partitions. Kafka guarantees that message order will be preserved within a partition (but not necessarily across all partitions within a topic).
Offset - The offset is a sequential numeric identifier that denotes a specific message's position in the partition.
We selected Kafka for the following reasons:
- Kafka’s ordering guarantee within a partition gives our system a critical serializability property: writes are applied in the same order on every service instance, even though we are producing messages to Kafka from multiple services. This is required for authorization operations.
- It was known to handle millions of messages per second. Our scale was orders of magnitude lower, but we wanted to ensure we would be able to scale the solution as we grew.
- Managed offerings of Apache Kafka offer availability SLAs of 99.99%, which would allow us to meet our availability requirement on write requests.
- Newly launched instances could read historical messages, which allowed us to scale out and ensure new nodes could catch up from a point-in-time snapshot (more on that later).
Our approach resembles a traditional event-sourcing architecture, so we had a lot of prior art to reference as we were designing the architecture. Most of how we use Kafka is not different from how it is used in a standard setting:
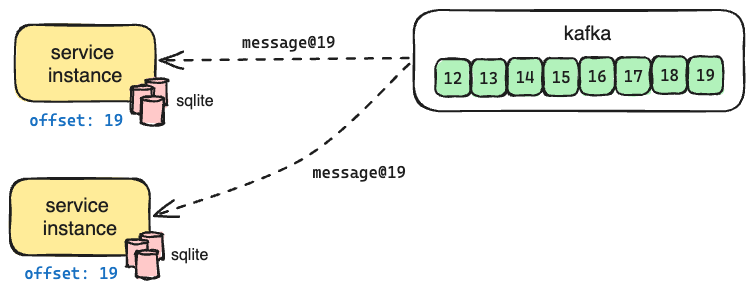
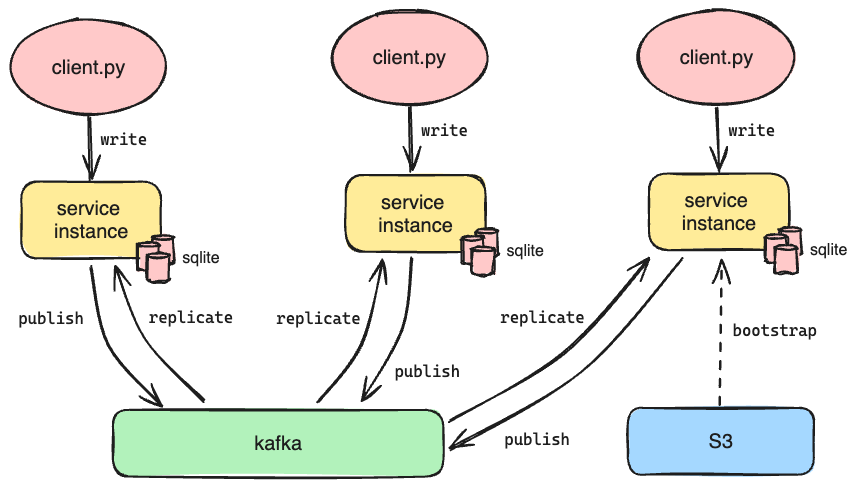
- When a given service instance receives a POST request, it doesn’t process it directly. Instead, it serializes the request and sends it to Kafka, recording the offset of the produced message.
- Each service instance listens to Kafka for new messages. When a new message is received, all instances receive it, apply its contents to their local SQLite database, and commit the message's offset to Kafka.
However, we do a couple of unique things that are driven by our architecture.
Configure each topic with a single partition
Kafka organizes messages first by topic and then by partition. A Kafka topic typically has multiple partitions to allow Kafka to support higher throughput for a given topic. However, ordering is only guaranteed within a single partition. While the environment is a natural partition key, Kafka may redistribute the keys if the number of partitions changes, which would happen if we needed to increase the partitions to support future growth. This change introduces a risk that messages for a single environment may be processed out of order when the partition changes, violating the serializability property we need. Because of this, we instead create new topics when we need to scale out, rather than adding partitions to existing topics. This gives us the control we need.
Record the offset of each message in application state
All Kafka libraries (we use rust bindings for rdkafka) already keep track of the offset; however, we also track the offset in application state to support a different functionality: bootstrapping new Oso Cloud service instances.
Because each Oso Cloud service instance has its own independent SQLite databases, whenever we launch a new instance, we have to initialize its local databases from scratch. It’s not realistic to do this by replaying every message in the history of Oso Cloud from Kafka. Instead, we need a way to initialize new instances from a recent and well-defined point in time.
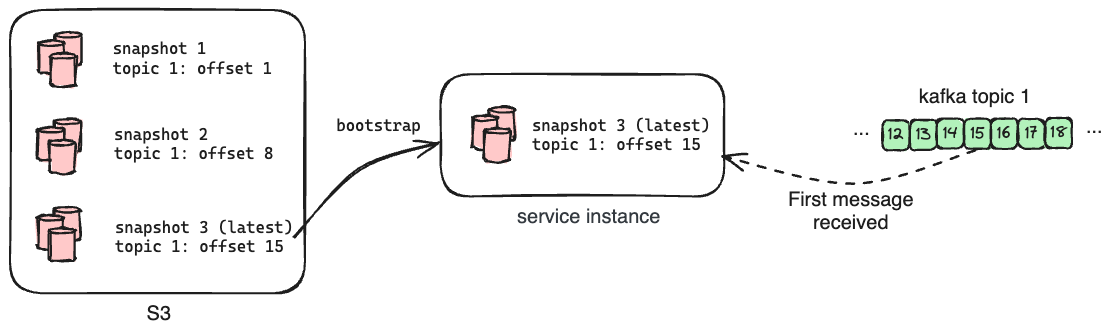
To achieve this, we have a dedicated Oso Cloud instance that listens to Kafka and processes all of the messages, but does not field external HTTP requests from clients. Its primary role is to make copies of its SQLite databases and upload them to S3 along with the offsets of each subscribed topic at the time of the upload. We call this copy a snapshot, and we generate one every 15 minutes.
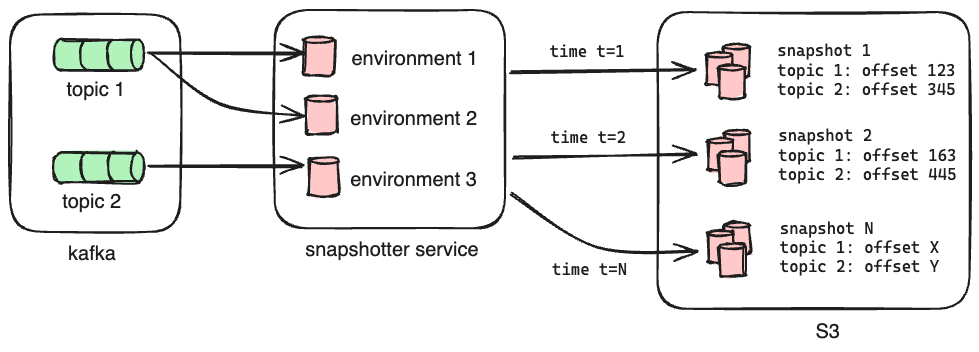
When we launch a new instance of Oso Cloud, it pulls down the latest snapshot as part of its initialization. This means any new instance is no more than 15 minutes out of date with the live service after loading its initial data. The instance then replays messages from Kafka starting from the recorded offsets for each topic in order to get the databases up to date before serving requests. Bootstrapping the instance from a recent snapshot in this way dramatically reduces the number of messages it needs to process - and by extension the amount of time required - to catch up to the head of subscribed topics.
Challenges
By replicating requests in this way, we can deploy multiple distinct instances of the Oso Cloud service that are backed by identical SQLite databases. This application architecture satisfies our requirements for availability, latency, and performance. But like any solution, we made some functional trade-offs when we adopted this model.
Real-time Ordering
One of the first questions our customers ask when we tell them about our architecture is how it handles real-time ordering. More specifically, if a user makes an authorization change, will subsequent queries reflect that change? The architecture does not provide a built-in mechanism to enforce real-time ordering. There’s a delay between the time that a service instance receives a write request and when that write is reflected in future read requests. We call this delay the replica lag. It reflects the time required to replicate the write to all Oso Cloud instances and persist it to the targeted SQLite databases. In practice, the replica lag is under 160 ms in the P99 case.
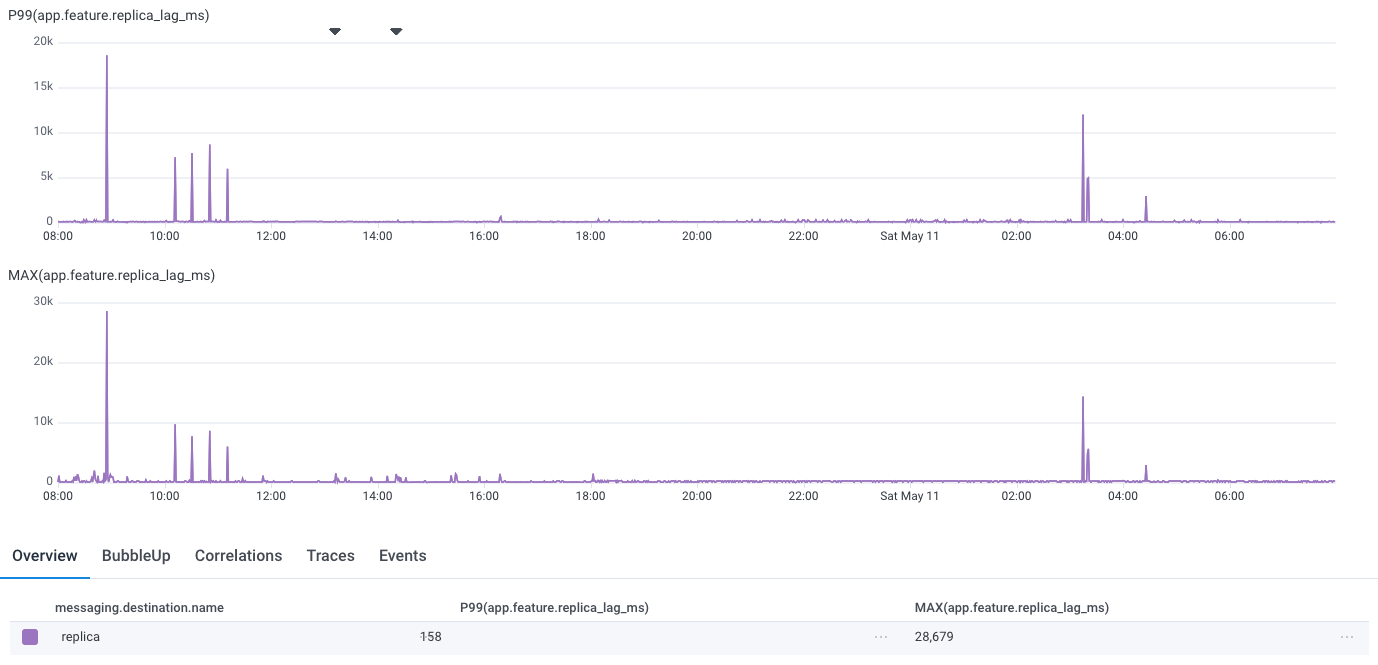
This lag is not noticeable in most cases where human users are making manual authorization changes (e.g., assigning a new role), but it is too long in automated cases where a change and a query may happen milliseconds apart. To address this use case, we leverage the offset to support read-your-writes consistency, which ensures that queries reflect completed writes initiated by the same client.

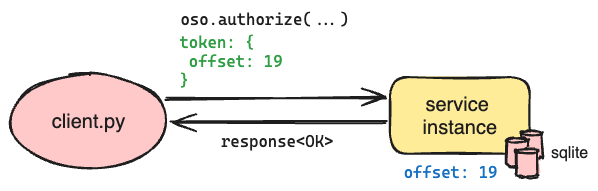
On a successful write request, we return an opaque token that includes the offset of the message; on a subsequent read request that provides the opaque token, we wait until the offset has been applied to the local SQLite database before running the query. This ensures that the query reflects the changes represented by the offset in the token.
Write Throughput
Kafka stores recent messages in its page cache to reduce the cost of serving recently produced messages. In our model, over 99% of Kafka reads are from the page cache, so the limiting factors to throughput are disk and network throughput. Our m5.2xlarge instances provide 593 MiB/s peak disk throughput and 1250 MiB/s peak network throughput. The typical message size for one fact is 300 bytes, which means our theoretical throughput is greater than 2 million facts/s. That’s more than enough - in theory.
Unfortunately, we don't observe this in practice because we have another limiting factor: SQLite. Because we process messages from a Kafka topic sequentially, we commit each write to SQLite as an individual transaction, which adds overhead. In our benchmarks, we've achieved a maximum throughput of 500 transactions/s when inserting a single fact per transaction. Our SQLite transaction throughput effectively caps the throughput of a given topic.
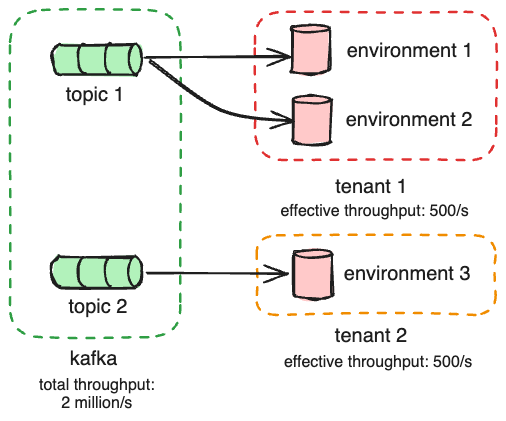
We need to process messages in parallel to increase our system write throughput. To maintain the ordering guarantee Kafka provides, we create new topics, each with a single partition, for each tenant. We can also create a topic per environment if we need to increase the write throughput further.
Benefits
Over the last two years of using this architecture in production, we’ve identified some unexpected benefits that have simplified elements of our operations.
Schema migrations
In a traditional n-tiered architecture, where the database is its own layer, deploying breaking schema changes may require applying changes to two database instances—one with the current schema and one with the desired schema—so they stay in sync before a cutover. Because we already replicate the requests, we can skip this step!
We recently completed a schema migration to move from a denormalized data model to the one we have now with a fact index and custom tables per fact type. To test out the performance of the new schema, we performed an offline migration of a recent snapshot and then deployed a service with the new code bootstrapped from the migrated snapshot. Once confident in the changes, we executed the same steps to deploy it to production.
Request replay and point-in-time recovery
We described how we replay messages from Kafka during bootstrapping of new instances to catch up to the head of the topics from a snapshot. We can use this same approach to recreate an exact copy of a SQLite database at any point in time. We offer this feature to our customers to eliminate the need to create manual backups.
On one occasion, we deployed a bug that intermittently locked local SQLite databases and prevented us from applying changes on rare occasions. After rolling back the change, we could revert to a snapshot from before we deployed the problematic change and replay all messages from that time. This situation was not ideal because some customers experienced temporary data loss and longer replica lag during the recovery, but the architecture enabled us to achieve a full recovery.
Conclusion
Two years after rolling out the original replicated request architecture with Kafka, the primary elements of the original design are unchanged: we process messages sequentially from each topic and use snapshots to bootstrap new instances. We have changed the underlying infrastructure to support the business's growth. Initially, there was only a single topic. We now we have one per paying customer. Instead of one set of SQLite databases per service instance, multiple service instances now share a set of SQLite databases to eliminate the bootstrapping step in most cases.
The system continues to meet the original requirements, and we've even realized some benefits. However, this system is far from complete. You may have noticed that we can only support up to 500 messages per second per environment, even with our most granular topic configuration. We also want to eliminate tail latencies in replica lag to ensure that the time required for an authorization change to be reflected in subsequent reads is imperceptible in all customer use cases. We're excited to solve these problems, and if they interest you, reach out to us on Slack or Schedule a 1x1 with an Engineer - or check our jobs page if you’d like to work on them with us!